Budget and finance tracking for me has always been a pain point. I've tried everything from google sheets to hledger but nothing really stuck. Because manually adding entries everyday is annoying, be it daily, weekly or monthly. So I built a pipeline to process my SMSs and update it automatically in a budget tracker. This is the story of that project.
First some background, I need a budget tracker because I'm prone to overspending. i need it to forecast future costs and plan ahead. My primary requirement is simple: data must be exportable. My secondary requirement is that it should be open source.
For the longest time (4 months), I used a simple excel file to track my expenses. I could enter data relatively quickly thanks to tab and keyboard movement, and I could make whatever budgets and charts I wanted. But I eventually dropped it because adding entries was still a hassle. My data entry flow was: open banking apps, check expenses, add them. If I did it daily, it would take 8-10 minutes, if I did it weekly, it would take an hour. And if I did it monthly, it would take 2-3 hours, plus I'd forget what half the expenses were for (because UPI transactions don't really show up with the personal messages in bank statements).
I eventually switched to some OSS app on android because adding transactions on phone seemed more convenient, but entering the data was still a bottleneck. I tried hledger, syncing the ledger between phone and laptop, but again, adding entries was painful. Until it finally hit me, if I can setup an API to ingest my incoming text messages, I could parse them and add them automatically. But I use multiple banks and different credit cards, each has their own SMS format. Heck, these banks have multiple formats for the same account. UPI transactions through GPay have different SMS alerts than those from paytm, the same credit card has different templates for different payment processors etc. And obviously templates change over time. So it wouldn't be as simple as having 2-3 regex patterns.
I had this idea a couple of years before GPT-3 was announced. At that time, BERT and other classical NLP techniques were king. And were not practical to implement for a small personal project. So I shelved this idea.
Fast forward to December 2025, and Google released Function Gemma. A 270M model optimized for tool calling. 270M is crazy small. Small enough that I can experiment with it without waiting days for training/finetuning to finish. So I decided, now is as a good a time as any to learn how to finetune LLMs. And I need a project to work towards, so I finally unshelved my SMS parsing idea.
To make the dataset, I need a ton of data. And iOS doesn't easily allow exports of SMSs. Luckily, before I switched to iOS, I already had exported my SMS data for past years. Which meant that I had an excellent corpus to use already. But it was all unannotated, there were OTPs, messaging about future debits, convos between my friends and plain spam also present.
So I leveraged some large models to annotate it. According to the internet, stuff is like quick work for todays' SOTA models. I experimented with claude, gpt and some oss models, but they were too slow. I had about 3000 messages to annotate and a timer of 30 minutes (I didn't want to spend too long on this). So I found out about Cerebras which has 1000 tok/sec on GLM4.6 and 3000 tok/sec on gpt-oss-120b which is bonkers. I loaded about 10$ there and started firing. I only used 1.2$ to parse all the messages. But now my dataset is ready.
Next up is finetuning. This is when I learned about LoRAs. I knew they existed and were used to modify the outputs of models but I had no technical knowledge of them. So I researched into it. Yes I could have directly finetuned the model as it was easily small enough, but I wanted to use LoRAs because that is something I could potentially use on larger models as well. After finetuning, I ran a comparison test between the original model and the finetuned one, the original had about 50% accuracy in terms of classification and correctly extracting the amount and credit/debit. The finetuned one had over 98%. In a production scenario, 2% wouldn't be acceptable, and you're right, but it took me only 30 minutes to get the model here, and I'm happy with this number so I'll move on. If anyone wants to improve on it, please feel free to take a shot at it. I then packaged the model into a gguf and then deployed it on a llama.cpp server.
Now that the model service is done, we still need a budget manager, and a way to get my SMS to the model.
For the budget manager, I used Actual Budget, it looks good, can be hosted on my server (so I can use my phone/laptop etc) and it has an interesting application of Envelope Budgeting. The only problem was that they did not have a HTTP API, they had a node package that could be used to interact with the app. Thankfully, someone had already used that package and built a HTTP API around it. So now I can programmatically add entries to my budget tracker.
To bring it all together, I built a simple fastapi server which will receive text messages from my phone via API, send it to the model for parsing and finally send the parsed response to Actual.
The last piece of the puzzle is: how do I send my text messages to the API? On Android, you can use Automate or Tasker to do this, on iOS you can use shortcuts/automation.
So the final flow is:
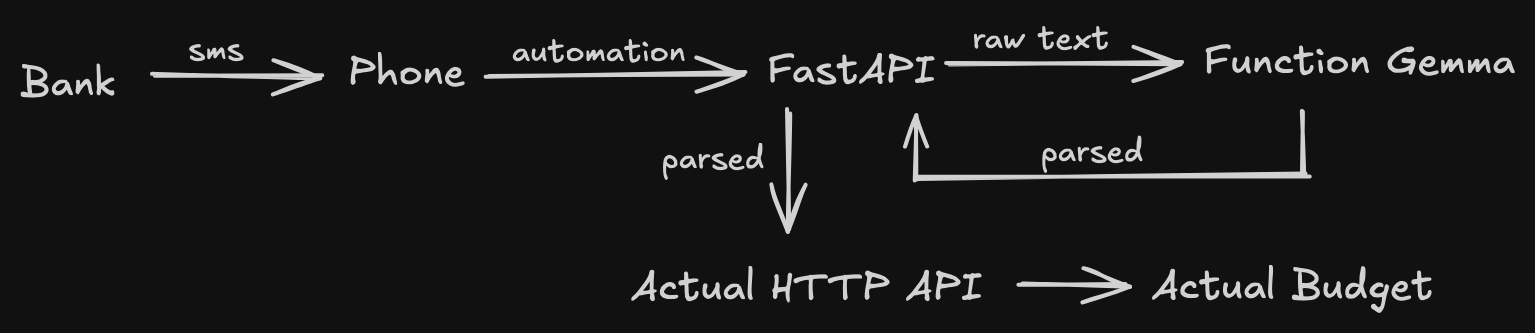
It's a little long, but it works.
Project is up
- github: kartikay-bagla/bank-sms-parsing
- model: kartikaybagla/functiongemma-bank-sms-parser
- docker image: kartikaybagla/bank-sms-api
Resources: